Site da disciplina de SBD do prof. Ilmério da Facom-UFU
http://www.facom.ufu.br/~ilmerio/sbd
Site da disciplina de SBD do prof. Ilmério da Facom-UFU
http://www.facom.ufu.br/~ilmerio/sbd
O Trabalho é individual e deve ser entregue manuscrito.
1. OBJETIVO
Implementar o protótipo de uma aplicação usando um SGBD conforme instruções a
seguir.
2. O QUE DEVE SER FEITO
• Definir o assunto da aplicação considerando um problema com o mínimo de cinco entidades, incluindo relacionamentos totais, parciais, de diferentes cardinalidades, além de especializações de entidades;
• Elaborar um diagrama conceitual DER para a aplicação;
• Mapear o diagrama conceitual para o modelo relacional;
3. O QUE DEVE SER ENTREGUE EM PAPEL(OU EM MEIO DIGITAL
EM FORMATO PDF)
• o modelo conceitual(Diagrama DER);
• O diagrama do modelo relacional
• uma análise de dependências funcionais e normalização do esquema relacional gerado por meio do mapeamento do EER;
Data de Entrega: Semana seguinte à da prova.
“O Objetivo básico do projeto de banco de dados é possibilitar ao usuário obter a informação exata em um limite aceitável de tempo, de maneira a executar sua tarefa dentro da organização” (Teorey e Fry)
“O Objetivo do projeto de um banco de dados relacional é gerar um conjunto de esquemas relacionais que nos permita armazenar informações sem redundância desnecessária, apesar de nos permitir recuperar a informação facilmente” (Korth e Silberschatz)
Sistemas de Gerenciamento de Base de Dados (SGBD) encapsulam do 3 ao 5 em um único processo, necessitando apenas ser Sintonizado (ou configurado)
Regras para encontrar Dependências Funcionais
Separação
A -> BC então A -> B e A -> C Exemplo:
CPF -> nome, endereço então CPF -> nome e CPF -> endereço
Leia o exemplo acima da seguinte maneira:
Se com um número de CPF eu encontro o nome e o endereço de uma pessoa, então com este mesmo número eu posso encontrar apenas o nome e com este mesmo número eu posso encontrar apenas o endereço.
Acumulação
A -> B então AC -> B
Exemplo:
CPF -> endereço então CPF, idade -> endereço
Leia o exemplo acima da seguinte maneira:
Se com um número de CPF eu encontro o endereço de uma pessoa, então com este mesmo número mais a idade da pessoa eu posso encontrar o endereço também.
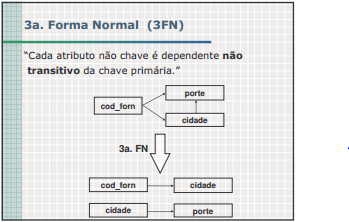
Transitividade
A -> B e B -> C então A -> C
Exemplo:
CPF -> código-cidade e código-cidade -> nome-cidade então CPF -> nome-cidade
Leia o exemplo acima da seguinte maneira:
Se com um número de CPF eu encontro o código da cidade de uma pessoa, e com o código da cidade eu encontro o nome da cidade, então com o número do CPF eu posso encontrar o nome da cidade.
Pseudo-Transitividade
A -> B e BC -> D então AC -> D
Exemplo:
CPF -> código-funcionário e código-funcionário, mês -> salário-funcionário então CPF, mês -> salário-funcionário
Leia o exemplo acima da seguinte maneira:
Se com um número de CPF eu encontro o código do funcionário, e com o código do funcionário mais um certo mês eu encontro o salário que ele recebeu naquele mês, então com o número do CPF mais um certo mês eu posso encontrar o salário que ele recebeu naquele mês.

Exemplo:
Está na FNBC: emp(ecod, ename, title), pay(title, sal),
É raro uma relação estar na 3FN e não estar na
FNBC, mas vejamos dois exemplos.
Exemplo de normalização até a FNBC
Seja o esquema de lotes a venda em um Estado:
lotes(propriedadeNum, cidade, loteNum, area, preco, imposto)
chaves primária: propriedadeNum;
DF1: propriedadeNum é chave primária
DF2: (cidade, loteNum) é chave candidata
DF3: cidade → imposto; % imposto fixo por cidade
DF4: area → preco; % preço por área independente
. % dos demais atributos
DF5: area → cidade; % domínio de tamanhos
. % disjuntos por cidade
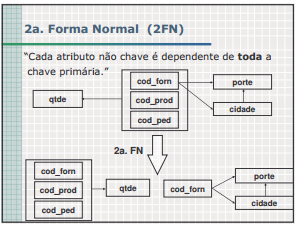
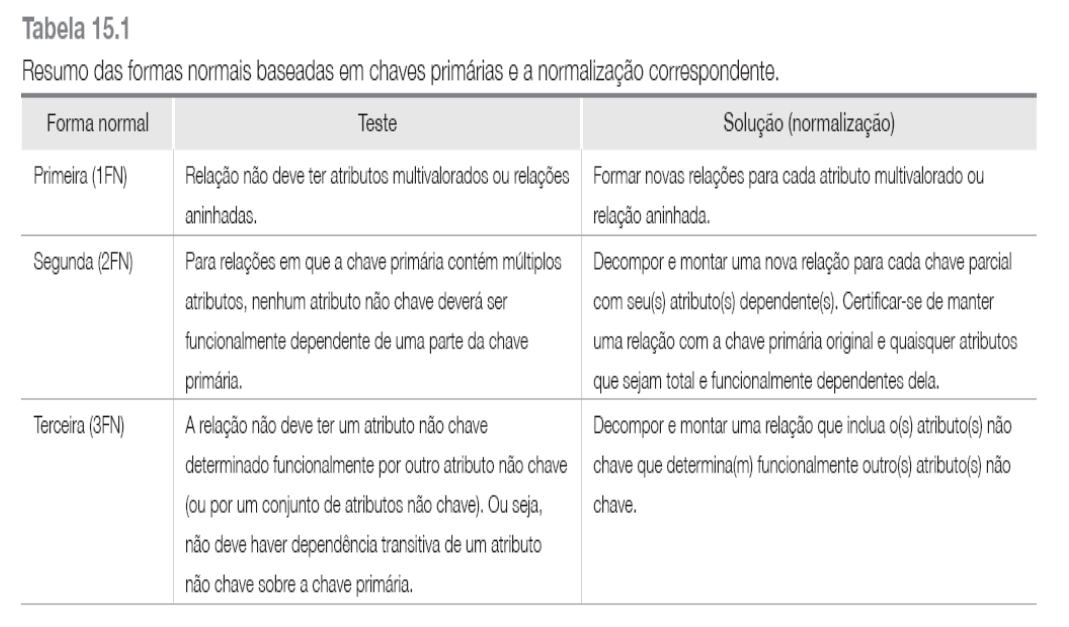
Está na 1FN? E na 2FN? E na 3FN? E na FNBC?
Exemplo lotes: 1FN
lotes(propriedadeNum, cidade, loteNum, area, preco, imposto)
Está na 1FN, mas não na 2FN, pois:
DF2: (cidade, loteNum) → propriedadeNum, area, preco, imposto
DF3: cidade → imposto
Imposto é parcialmente dependente da chave
(cidade, loteNum)
Exemplo lotes1 e lotes2: 2FN
lotes1(propriedadeNum, cidade, loteNum, area, preco)
lotes2(cidade, imposto)
lotes2 está na 3FN;
lotes1 está na 2FN, mas não na 3FN, pois:
DF4: area → preco;
– area não é superchave e preço não é atributo principal
Exemplo lotes1 e lotes2: 3FN
lotes1a(propriedadeNum, cidade, loteNum, area)
lotes1b(area, preco)
lotes2(cidade, imposto)
Lotes1a, lotes1b e lotes2 estão na 3FN, mas
lotes1a não está na FNBC, pois:
DF5: area → cidade;
Observe que lotes1a está na 3FN porque, embora area
não seja superchave, cidade é atributo principal.
Entretanto isso não é relevante para a FNBC
Exemplo lotes na FNBC
lotes1ax(propriedadeNum, loteNum, area)
lotes1ay(area, cidade)
lotes1b(area, preco)
lotes2(cidade, imposto)
Observe que a DF2 foi perdida nesta decomposição
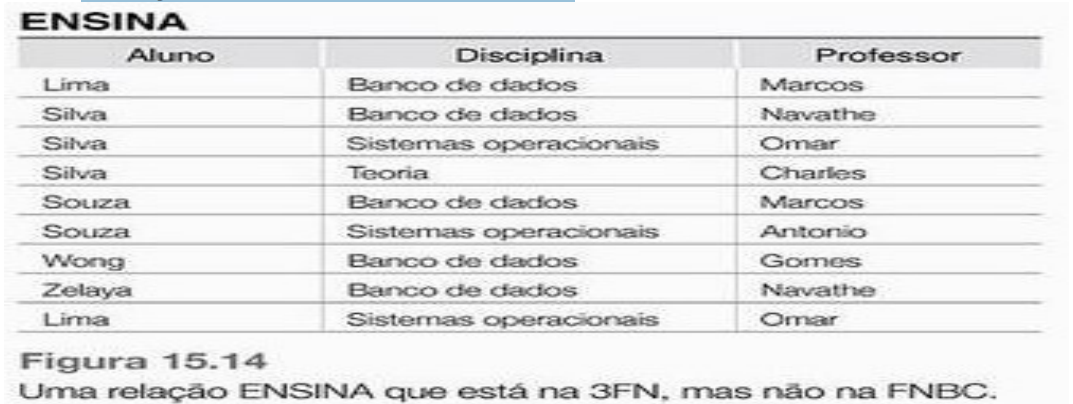
Outro Exemplo de 3FN x FNBC
ensina(aluno, disciplina, professor)
DF1: {aluno, disciplina} → professor;
DF2: professor → disciplina; % cada professor
% leciona uma disciplina
1FN: atributos são atômicos? Sim
2FN: há dependência parcial? Não, logo está na 2FN
3FN: dependências de superchaves ou apontando para
atributos principais? sim, logo está na 3FN
FNBC: dependências de superchaves? Não, veja DF2
Como decompor ensina?
Alternativas de decomposição na FNBC
1. (aluno, professor), (aluno, disciplina)
2. (disciplina, professor), (aluno, disciplina)
3. (disciplina, professor), (aluno, professor)
Todas perdem DF1, mas em 3. evitamos tuplas falsas após
uma junção. Ex. de instância:
Estudo para a Prova:
Construa um Diagrama Modelo Entidade Relacionamento tabular (Relacional) agrupando os atributos nas tabelas que vão representar as entidades e os relacionamentos do seu banco de dados
Construa os diagramas de dependências funcionais para as tabelas propostas (Diagrama relacional)
Garanta que cada atributo será atômico (isto, é, não pode ser dividido) para se obter um modelo na 1a. FN
Elimine as dependências parciais da chave primária em suas tabelas para obter um projeto na 2a. FN
Elimine as dependências transitivas nas tabelas (se houver), obtendo um esquena na 3a. FN
regras para mapeamento do Modelo Conceitual de Alto Nivel para o modelo Relacional (de mais baixo nivel)
1: Do Diagrama Conceitual (DER)
Tipos de Entidade (E)
Mapeadas em Relacionamentos (R)
Usando todos os atributos encontrados em (E)
A chave primária de E se torna chave primária em R
Atributos compostos de E possuem suas folhas mapeadas em R
Todos os outros atributos simples são mapeados na relação R
Atributos Multivalorados não são aplicados a essa regra
2: Se tivermos um atributo multivalorado
Cria-se uma relação com o nome do atributo multivalorado
Ex: Grau de escolaridade
Chave Estrangeira (ex: Profissional_ID)
Intenção da Relação (Nome do Grau de Escolaridade)
Ambas são uma chave primária composta
3a. Regra: Tipos de Entidades Fracas
Tipos de Entidades Fracas: Tipos entidade que não têm seus próprios atributos-chave são chamados tipos entidade fraca
Entidades, que pertencem a um tipo entidade fraca, são identificadas por estarem relacionadas a entidades específicas do outro tipo entidade, por meio da combinação com valores de seus atributos
Chamamos esse outro tipo entidade identificador ou tipo entidade proprietária, e chamamos o tipo relacionamento entre o tipo entidade fraca e seu tipo proprietário de relacionamento identificador do tipo entidade fraca.
Sempre possui uma restrição de participação total (dependência de existência) em relação a seu relacionamento identificador, porque uma entidade fraca não poderá ser identificada sem um tipo proprietário
Nem toda a dependência de existência resulta em um tipo entidade fraca.: Por exemplo, uma entidade CARTEIRA_HABILITACAO não poderá existir a menos que esteja relacionada a uma entidade PESSOA, embora tenha sua própria chave (NumeroLicenca) e conseqüentemente não seja uma entidade fraca.
Segue a regra número 1:
Pega-se a chave primária da entidade fraca (pertencente à entidade pai) e a transforma em uma chave primária parcial do Relacionamento da Entidade Fraca
Atributos compostos de E possuem suas folhas mapeadas em R
Todos os outros atributos simples são mapeados na relação R
Adendo:
Verificar o tipo de relacionamento entre o Tipo Entidade Forte e Fraca:
Compõe a chave primária um código primário derivado da entidade pai e
Verificar se o relacionamento entre a entidade forte e fraca possui atributos
atributos podem fazer parte da chave primária
4a. Regra: O que se fazer com um relacionamento 1:1
Chave estrangeira pode estar em qualquer um (mas em apenas um) dos relacionamentos.
Normalmente utiliza-se discernimiento do contexto para identificar em qual
Excessão:
Quando o relacionamento possui atributos (ver regra 6)
5a. Regra: O que se fazer com um relacionamento 1:muitos
Chave estrangeira:
O relacionamento “muitos” é quem levará a chave estrangeira, sendo essa a chave primária do relacionamento “1”
Excessão:
Quando o relacionamento possui atributos:
atributos seguem a chave estrangeira (permanecendo no lado: “muitos”)
6a. Regra: O que se fazer com um relacionamento muitos:muitos
Cria-se uma tabela de relacionamento… (ou um relacionamento de relacionamento)
(inclui excessão à regra 4)
7a. Regra: Herança
Funciona como um tipo entidade fraca.
Álgebra Relacional
Importante pois:
Satisfaz o processo matemático para o componente manipulativo proposto por Codd
É o “ancestral” das linguagens manipulativas (SQL)
Não está “morta”, é usada mais para otimização e prova
Usada para
Mover ou manipular grupos de dados
Séries de Operações
Operações tradicionais de Conjuntos
União, Intersecção, Subtração e Produto Cartesiano
Os 3 primeiros requerem que as 2 tabelas manipuladas sejam compativeis em União:
Possuem o mesmo grau
Um atributo de uma tabela está no mesmo domínio da outra tabela
União
A+B = C
Intersecção
A.B = D
Subtração
A-B = E tal que E.B = Vazio
Produto Cartesiano <A,B>
Tabelas de Diferente Graus (ou não compatíveis em União)
Grau resultante = G(A)+G(B)
Cardinalidade resultante = C(B)*C(B)
Outros Operandos
Operadores Relacionais Especiais em Tabelas
Renomear (ρ)
Renomeia a tabela para o novo nome. Muito util para renomear tabelas resultantes que serão utilizadas mais de uma vez
ρ novo nome (tabela original)
Restrição (Selecione atributo de tabela Condicionado a…)
Simbolo Sigma (σ)
Subscrito é a condição
Superscrito é a Tabela
Select relação with condição given tabela
Projeção (π)
Remove colunas reduzindo o grau da tabela
Pode ser combinado com o operador de restrição
Usa-se o símbolo pi (produtório)
Subscrito as colunas a se recuperar
Superscrito a tabela
projection (a1,a2) from (tabela)
Junção Natural(Join)
O atributo Join deve ser compatível com produto
(Chave Estrangeira em uma tabela e Chave Primária em outra)
Atributo de Agregação devem estar no mesmo domínio
Realiza-se um produto cartesiano e remove-se as tuplas que não se encaixam
Usa-se o símbolo(Ψ)
T1 Ψ(T1.att1=T2.attx) T2
Join R1 Using R1.att with R2 Using R2.att
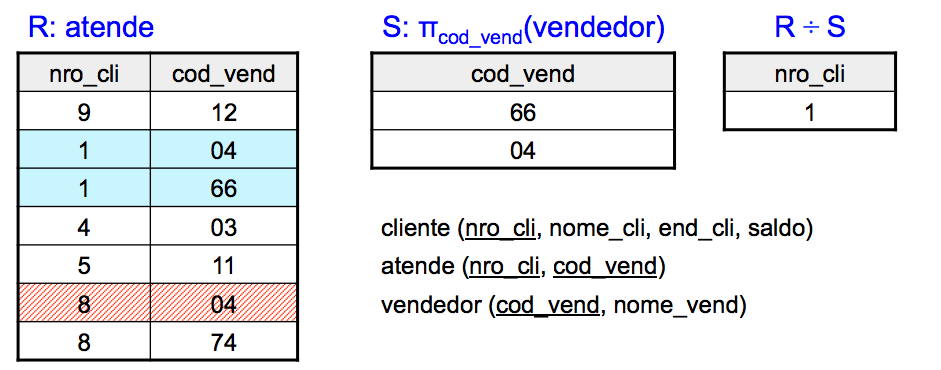
divisão
• Divisão de duas relações R e S
– todos os valores de um atributo de R que fazem referência a todos os valores de um atributo de S
• Utilizada para consultas que incluam o termo para todos ou em todos
Liste os números dos clientes que já foram atendidos por todos os vendedores.
agregação
Permite a utilização de funções de agregação
Modelo de Dados Relacional (Modelo Lógico)
O mais importate
Do tipo de modelos lógicos
Proposto por E. F. Codd (Ganhou o prêmio Phillips pela proposta) (1970)
Proposta seria corrigir os problemas dos modelos anteriores
Modelo Matemático utilizando Teoria dos Conjuntos
Dados são representados em Tabelas (tb chamados relacionamentos ou visões)
Cada linha é uma tupla (tb chamada de registro)
Cada coluna é chamada de atributo e identificada por nomes
Colunas não precisam estar em uma ordem especificada
Em uma tabela não se pode ter duas colunas com o mesmo nome
Em tabelas diferentes sim
Pode ser associada a outra tabela
Possui chave primária
Domínio de Atributos
Todas os valores possiveis do atributo
Ex: Nota = 0.0 a 100.0
Fáceis (Nota)
Difíceis (Nome) (que tipo de nome?)
Facilitando:
Domínio dos Primeiro Nomes
Domínio das Iniciais do Meio
Domínio dos Sobrenomes
Grau de uma Tabela
Número de atributos de uma tabela
Difere do Grau do modelo Semântico
Uma tupla é uma agregação de valores de todas as informações (ou descrições) de um determinado dado
Cardinalidade
Número de tuplas em uma tabela
Difere do modelo semântico
3 Objetivos:
Independência de Dados
Independência Física
Comunicabilidade
Modelo fácil de entender
Modelo Sectarizado
Tudo é uma tabela
Processo matemático (Codd era um matemático)
Independência de Implementação
Relacionamentos seriam realizados de forma lógica
Linguagens de Alto nível para criar e manipular dados (DDL – DML)
Deve responder a um conjunto de regras para manutenção de integridade
Normalização
3 componentes chaves
Componente estrutural
Mais que uma tabela 2D
Ordem dos atributos ou das tuplas não importam
Não se pode ter 2 atributos com o mesmo nome na mesma tabela
Tratamento sistemático de valores NULL
Cada tupla deve ser distinta
Identificador de unicidade (chave primária)
valor de atributo deve ser escalar
Nao ha multiplos valores
não há atributos compostos
Atributos devem ser atomicos
Componente de Integridade
Integridade de Entidade
Chave primária para ident. cada tupla distinta
Não pode ter valores NULL
Integridade Referencial
Chave Estrangeira
Pode ser NULL
Integridade Definida pelo Usuário
O Modelo em Si deve prover algum meio de integridade definida pelo usuário (ou regras de negócio)
Componente Manipulativo – componente chave
Deve se ter uma Linguagem de Definição de Dados e Linguagem de Manipulação de Dados (LDD e LMD) mínimas
Opera-se em um sistema matemático fechado
T1 op T2 = T3 op T4 = T5 op T6 =T7
Inicialmente criaram o SQL que já supriram os requerimentos
1. Introdução
. O que e um banco de dados (BD)
. O que e um sistema de gerencia de banco de dados (SGBD)
. Paradigmas de SGBD
. Aplicações para um BD
O que é um sistema:
Um conjunto de processos que trabalham em conjunto para um determinado fim
Quais seriam os componentes de um sistema? (falar de sistemas comuns)
Todos os sistemas possuem os mesmos componentes em comum
Entrada
Processo (um laço de retroalimentação) e
Saída
Um sistema pode ser um supersistema, onde os processos são por si só sistemas
Em um Sistema de Informação as entradas são denominadas de Dados, uma coleção de elementos que não possuem significado.
Dados passam pelo processo que é a aplicação ou algoritmo e é transformada em algo significativo para um usuário.
Nesse contexto: O que seria um Sistema de Banco de Dados?
E um Sistema de Gerenciamento de Banco de Dados?
Pensem por um tempo enquanto os paradigmas são apresentados:
Modelo de Dados do tipo Lógico
Modelos são abstrações de uma entidade do mundo real
Seus benefícios:
Tem complexidade reduzida
São mais baratos
Mais importante: Modelos são criados para que a sua idéia abstrata seja quebrada
Novas e melhores idéias abstratas do modelo seja criada
Modelo de Dados Lógico
Modelos de baixo nível um passo distante dos produtos que os implementam
Um exemplo são os Sistemas de Arquivos, responsáveis por persistirem os dados desejados no disco rígido, USB, CD/DVD, disquetes, Fitas Magnéticas, etc.
Em uma abstração eles são basicamente um sistema de arquivos real, como o baseado em papéis, pois era como sabíamos como organizar os dados sobre o espaço.
Resulta em diversos problemas. (Discutir os problemas)
O que acontece quando o modelo lógico de um programa tenta se comunicar com outro modelo lógico de outro programa?
IBM tentou solucionar o problema criando o modelo de dados Hierárquico (B-Trees, B+-Trees)
Geralmente produtos baseados em Arquiteturas de Mainframes e altamente acoplado com o sistema (COBOL)
Apresenta um problema (Relacionamentos um pra um ou um pra muitos, ok, mas e muitos pra muitos? Explicar com uma árvore no quadro)
Para se alcançar ou caminhar de uma entidade a outra era muitas vezes necessário utilizar códigos de localização previamente escrito (previamente planejado)
O que aconteceria ao se remover (ou incluir) um nó?
Era efetivo?
Foi como começou a se pensar organização de dados
O processo de ligações codificadas foi um ensinamento que permitiu saber que se torna bem rápido
Modelo de Dados em Rede (Grafo)
Ainda Codificado com o sistema
Modelo de dados Relacional
Modelo Matemático (teoria dos conjuntos)
Modelo de dados Conceitual
Um modelo de abstração mais alta e mais abrangente
Arquitetura ANSI-SPARC
Modelos lógicos criam o problema de Dependencia dos dados
Problema de reescrita do programa quando estrutura dos dados mudava
Como resolver esse problema? Foi enviado à ANSI para resolver
Solução em um nível de hierarquia mais alta de responsabilidades
Arquitetura similar à MVC (Explicar)
Esquema de Visão (Modelo de Interação)
Esquema Conceitual (Modelo Lógico)
Esquema Interno (modelo físico)
Modelo de Dados Semânticos
Modelos de nível mais alto com mais significados
Peter Chang DER (1976)
Esquema conceitual respresentado pelo DER
DER Estrutura simples
Tipos de abstrações como Entidades (Retângulos), Atributos (Oval) ou associações (forma de diamente)
Atributos Simples ou Compostos
Atributos de Múltiplos Valores (duplo oval)
Atributos Processados (Oval pontilhado)
Diferentes tipos de atributos
Chaves: Candidatas ou Alternativas
Candidata te identifica unicamente
Não precisa ser apenas um atributo, pode ser um grupo de
Alternativa pode te identificar unicamente, mas depende da primeira
Conceito de Multiplicidade e Cardinalidade (um a um, um a muitos, muitos a muitos)
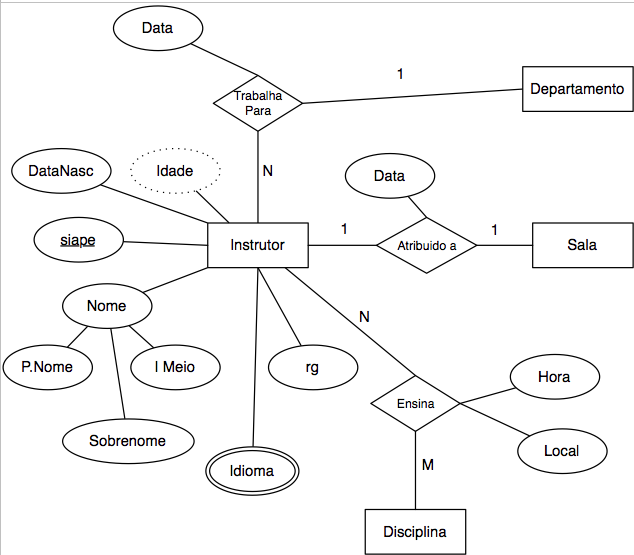
Grau de um relacionamento
Como os relacionamentos se relacionam com as entidades
União: Relacionamento em uma mesma entidade:
Empregado – gerencia – Empregado
Binário: 2 entidades
Estudante – Cursa – Disciplina
Ternários…
N-Ários
Informações podem ser quebradas em outras informações estáticas
Informações Dinâmicas (Transações)
Muito bom para modelar informações estáticas, mas não as dinâmicas.
Modelo de Dados Relacional
O mais importate
Do tipo de modelos lógicos
Proposto por E. F. Codd (Ganhou o prêmio Phillips pela proposta)
Proposta seria corrigir os problemas dos modelos anteriores
Modelo Matemático utilizando Teoria dos Conjuntos
Dados são representados em Tabelas (tb chamados relacionamentos ou visões)
Cada linha é uma tupla (tb chamada de registro)
Cada coluna é chamada de atributo e identificada por nomes
Colunas não precisam estar em uma ordem especificada
Em uma tabela não se pode ter duas colunas com o mesmo nome
Em tabelas diferentes sim
Pode ser associada a outra tabela
Possui chave primária
Deve responder a um conjunto de regras para manutenção de integridade
Ementa
SGBD: histórico e características. Modelo Relacional: conceitos, restrições de integridade, dependência funcional, formas normais. Álgebra relacional. SQL: linguagem de definição, linguagem de manipulação, visões. Modelagem conceitual.
BIBLIOGRAFIA BÁSICA
Date, C. J., 1941-. Introdução a sistemas de bancos de dados. Rio de Janeiro: Campus, 1990.
SUDARSHAN, S.; SILBERSCHATZ, Abraham; KORTH, Henry F. Sistema de banco de dados. 3. ed. São Paulo: Makron Books, 1999.
DATE, C. J. . Introdução a sistemas de bancos de dados. 9. ed. Rio de Janeiro: Campus, 1990.
BIBLIOGRAFIA COMPLEMENTAR
Freytag, Johann Christoph; Maier, DavidVossen, Gottfried. Query processing; for advanced database systems. San Mateo: Morgan Kaufmann.
SILVA, Luciano Carlos da . Banco de Dados para Web: do planejamento à implementação. São Paulo: Érica, 2001.
COUGO, Paulo Sérgio . Modelagem conceitual e projeto de bancos de dados. Rio de Janeiro: Campus, 1997.
ELMASRI, Ramez; NAVATHE, Shamkant B. . Sistemas de banco de dados. 4.ed.. São Paulo: Pearson, 2005. 723 p. Titulo original: Fundamentals of database systems.
Apresentados os mecanismos de cooperação entre processos diversas dúvidas nos são apresentadas: Como posso sincronizá-los, o que acontece quando ocorre deadlock (o que é deadlock)? Como resolver esses problemas? Quais são as técnicas e como elas funcionam.
O trabalho tem, portanto, uma finalidade de pesquisa. Utilize-se da internet e da bibliografia apresentada para elaborar um trabalho manuscrito apresentando um estudo sobre a comunicação entre processos, os problemas que podem decorrer da mesma e como resolvê-los.
Data de entrega: Dia da prova.
Bom trabalho e boas pesquisas.
Problema do Produtor/Consumidor
Buffer fixo (Mem. Compartilhada)
#define BUFFER_SIZE 10
typedef struct {
…
} item;
item buffer[BUFFER_SIZE];
int in=0;
int out=0;
#define BUF_FILL (((in+1)%BUFFER_SIZE)==out)
item nextProduced;
while(1){
/**/ while(((in+1)%BUFFER_SIZE)==out)
/**/ ; /* não faz nada!*/
/**/ buffer[in]=nextProduced;
/**/ in=(in+1)%BUFFER_SIZE;
}
item nextConsumed;
while(1) {
/**/ while(in==out)
/**/ ; /* não faz nada */
/**/ nextConsumed = buffer[out];
/**/ out=(out+1)%BUFFER_SIZE;
}
Comunicação entre processos (IPC)
Decisões de implementação
Comunicação Direta
Comunicação Indireta
Sincronização de Primitivas
Controle de Espaço no Canal